ROW_NUMBER, RANK, DENSE_RANK, NTILE, PIVOT, UNPIVOT, OUTPUT, CROSS APPLY, OUTER APPLY, EXCEPT, INTERSECT, BEGIN TRY, END TRY, BEGIN CATCH, END CATCH, C# Assembly,CLR, Common Table Expression (CTE)
SQL Server 2005 ile birlikte T-SQL dilinde güncellemeler, yeni ifadeler geliştirildi. Bu yeni gelen özelliklerden bazıları DDL (data definition language) bazıları da DML (data manipulation language) tarafında gerçekleştirildi. Bunların başında PIVOT ve UNPIVOT komutları, CTE, DDL Trigger, exception handling(TRY/CATCH block), TOP ifadesinin genişletilmesi, OUTPUT ifadesi gelmektedir. Bu yazıda bu yeni özellikleri örneklendireceğiz.
Geliştirilmiş TOP Operatörü
Bilindiği gibi T-SQL’deki TOP operatörü, kaynaktan ilk n kayıdın getirilmesini veya kayıtların belli bir yüzdelik kısmının getirilmesini sağlar. SQL Server 2005 ile birlikte TOP operatörünün yeteneği geliştirildi ve artık kayıt sayısını veya yüzelik miktarını parametrik olarak alması sağlandır.
DECLARE @KacKayit int SET @KacKayit = 30 SELECT TOP (@KacKayit) MusteriId,AdSoyad FROM Musteri
SQL Server 2005 ile birlikte TOP operatörünü, UPDATE, DELETE ve INSERT işlemlerinde de kullanma imkanı bulduk.
--Aşağıdaki ifade, Musteri tablosunun ilk 2 kaydını günceller. UPDATE TOP(2) Musteri SET Meslek='Öğrenci' --Musteri tablosunun ilk 2 kaydını siler DELETE TOP(2) Musteri --Musteri1 tablosundan yalnız 2 kaydı Musteri tablosuna ekler INSERT top(2) Musteri SELECT * FROM Musteri1
Aynı şekilde TOP operatörüne bir subquery’i de parametre olarak geçebiliriz.
--Musteri tablosundan Musteri1 tablosu kadar kayıt getirir SELECT TOP(SELECT COUNT(*) FROM Musteri1) * FROM Musteri
Derecelendirme İfadeleri(Ranking Function)
Tablolardan çektiğimiz verileri çalışma anında sıralamak için kullanabileceğimiz özel sıralama fonksiyonları geliştirildi.
Bu fonksiyonları örneklendirmeden önce aşağıdaki gibi tablo oluşturalım.

ROW_NUMBER
Bu fonksiyon her satırı sıralama ifadesine göre 1’den başlayarak ardışık olarak numaralandırır.
ROW_NUMBER() OVER ([
ROW_NUMBER() OVER ([
)
Tablomuz için Sehir ve UyeId kolonlarına sıralama yaparak numaralandırma yapalım
SELECT ROW_NUMBER() OVER(ORDER BY Sehir) SehirSira, * FROM UYE ORDER BY Sehir, UyeId

Bu sıralamayı her satır için ayrı yapmak yerine başka bir kolonun tekil olup olmasına bağlı olarak ta yapabiliriz. Örnekteki değerlere göre mesleğe bağlı olarak şehirleri sıralayalım.
SELECT ROW_NUMBER() OVER(ORDER BY Sehir) SehirSira, ROW_NUMBER() OVER(PARTITION BY Meslek ORDER BY Sehir) as MeslegeBagliSehirSira, * FROM UYE ORDER BY Sehir, UyeId
Nasıl bir sonuç geleceğini öğrenmek için örneğin “Müh” üzerinden gidelim. Tabloda Müh’leri alıp Şehir’e göre sıralayalım ve sonra numaralandıralım.

RANK() ve DENSE_RANK() fonksiyonları
RANK() ve DENSE_RANK() fonksiyonları ile verilen bir sütuna göre her bir grup için aynı sayı değeri üretilerek sıralama yapılır. Aralarındaki fark, RANK() fonksiyonu, değişen her grup için başlangıç satırının satır numarası ile sıralama yaparken, DENSE_RANK() fonksiyonu gruplar arası geçişte bir artan sayı üretir.
Bölümlendirilmiş kayıt setinde RANK() fonksiyonu, her bölüme bir sıralama numarası verir. Her bölüm içindeki aynı kayıtlar aynı sıralama numarasına sahip olur. Sonraki bölüme geçildiği zaman önceki sıralama numarası, önceki bölümdeki kayıt kadar atlar yani bölümler ardışık numaralandırılmaz. Her bölüme ardışık numaralandırma yapılacaksa DENSE_RANK() kullanılır. Aşağıdaki şekilde bu metodlar, tablodaki Sehir kolonuna uygulanmıştır.

Bu iki fonksiyonda, aynı değere sahip satırlar, aynı sıralama numarasını alırlar.
NTILE(
NTILE() kayıt setinde OVER ve ORDER BY ile belirtilen kolonlara göre sıralama yapar ve kayıtları parametre olarak aldığı sayıya bölerek her bölüme ardışık sıra numarası verir.
NTILE (integer_expression) OVER ( [ < partition_by_clause=""> ] < order_by_clause=""> )
integer_expression parametresi, gruo sayısını bildiren pozitif bir tam sayıdır. Sorgu sonucunda 30 kaydın döndüğünü ve NTILE() fonksiyonuna 5 parametresinin gönderildiğini düşünelim. Bu durumda her biri 6 satırdan oluşan 5 grup oluşturulur. Ve her gruba 1’den başlamak üzere ardışık numaralandırma yapılır yani ilk 6 kaydın numarası 1, sonraki 6 kaydın numarası 2 ve son 6 kaydın numarası 5 olarak set edilir.
Örneğimizde 8 kayıt var, bu kayıtlar arasında 5 grup oluşturalım. Sıralam yine Sehir kolonuna göre yapılacak.
SELECT NTILE(5) OVER(ORDER BY Sehir) [NTILE], * FROM UYE ORDER BY Sehir

DDL Trigger
SQL Server 2000’e kadar ancak tablolar üzerinde Insert, Update, Delete işlemlerinde tetiklenmek üzere triggerler yazabiliyoruz(DML trigger). SQL Server 2005 ile birlikte CREATE, ALTER, DROP, GRANT ve REVOKE gibi DDL veya DCL ifadeleri için de trigger yazılabilmektedir(DDL trigger). Yani database ve nesneleri üzerinde herhangi bir DDL ifadesi çalıştığı zaman tetiklenecek bir trigger oluşturulabilecek. Tanımlanması ve kullanımı kolay olan bu trigger için hangi event için tetikleneceğini belirtmemiz gerekir.
Örneğin aşağıdaki satırlarda DROP_TABLE eventi için bir trigger tanımlanmıştır. Bu trigger tanımlı olduğu database içerisinde herhangi bir tablo silinmeye çalışıldığı zaman devreye girer. Burada yaptığımız iş böyle bir durumda silme işleminin iptal edilmesi, roll back işleminin yapılmasıdır.
CREATE TRIGGER trg_TabloSilme ON DATABASE FOR DROP_TABLE AS ROLLBACK
Common Table Expression (CTE)
SQL Server 2005 ile birlikte gelmiş CTE yapıları, kullanım biçimleri view veya türemiş tablolara benzeyen, fiziksel olarak saklanmayan anlık olarak oluşturulan, yalnızca bir kere tanımlanıp aynı kod bloğunda birden fazla kullanılabilen özellikle recursive(özyinelemeli) işlemlerde performans sağlayan yapılardır.
CTE’lerin tanımlanma biçimi şu şekildedir:
[WITH
expression_name
[(column_name [,...n])]
AS
(
Burada WITH ifadesi, CTE’nin adını ve içerdiği kolonları belirtmek için kullanılır. Oluşturulan bir CTE’yi kullanmak için bir tablo gibi adını FROM’dan sonra çağırmak yeterli olacaktır.
Basit bir CTE örneği verelim.
WITH Kisi(C1, C2) AS (SELECT 10, 'Ali') SELECT * FROM Kisi /*C1 C2 ------------ 10 Ali */
Biraz daha gelişmiş bir örnek oluşturalım. Aşağıdaki SATIS tablosunda her dönemin satış miktarları verilmiştir.

Bu tablodaki kayıtları döneme göre özetleyip her dönemin karşısına o dönemdeki toplam satış miktarını ve kendinden önceki ayın satış miktarını yazdıralım.

Bu sonucu CTE ile aşağıdaki gibi oluşturabiliriz.
WITH cteSatis(Donem, Deger)
AS
(
SELECT Donem, SUM(Deger) FROM SATIS
WHERE Firma=1
GROUP BY Donem
)
SELECT
a.*,
b.Deger AS Onceki
FROM
cteSatis AS a
LEFT OUTER JOIN cteSatis AS b
ON a.Donem = b.Donem + 1;
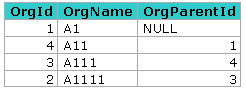
CTE’lerin asıl anlam kazandığı özyinemeli(recursive) bir örnekte kullanalım. Organizasyon şemasının bulunduğu ORG tablosu olduğunu düşelim.

Bunun normal rekürsif metodla yapacak olsaydık bir grubun altındaki alt grupları bulan bir fonksiyon yazıp her defasına onu çağıracaktık. Ama CTE bunun daha kısa bir yöntemle yapar. CTE içerisinde sonraki sonuçları önceki sonuçlarla birleştirmek için UNINON ALL ifadesi kullanlır.
WITH CTESet(Kolon seçimi) ( --Başlangıç aşaması UNION ALL --Biriktirme aşaması )
Buradaki “başlangıç aşaması” derinliği artan ağacın rootunu temsil eder. Ağacın en üstündeki kayıt hangisi olacaksa onun query’si yazılır. “Biriktirme aşaması” ise her defasında tekrar edecek olan querydi.
WITH cteORG(OrgId,OrgName,OrgParentId) AS( SELECT * FROM ORG WHERE OrgParentId IS NULL UNION ALL --Bu bölüm döngüsel olarak çağrılır SELECT a.* FROM ORG a INNER JOIN cteORG b ON a.OrgParentId = b.OrgId ) SELECT * FROM cteORG
OUTPUT operatörü
OUTPUT ifadesi, o anda yapılmış INSERT, UPDATE veya DELETE işlemlerinden etkilenen kayıtları parametre olarak aldığı tabloya aktarır. Böylece yeni oluşturulmuş veya sorgu sonucu güncellenmiş veya silinmiş kayıtları kolaylıkla yakalayabiliriz. OUTPUT ifadesi, trigger yapılarında olduğu gibi silinmiş değerleri veya güncellenen kayıtların önceki değerlerini DELETED, eklenmiş kayıtların veya güncelleme esnasında güncel değerleri INSERTED tablosundan okur. Bu tablolar o anda oluşan sanal tablolardır.
--Değişiklikleri aktacağımız tabloyu oluşturalım DECLARE @Guncelle AS TABLE (MusteriId int, OncekiTelefonKod char(50),YeniTelefonKod char(50)) --Tablodaki SehirId kolonu 2 olan kayıtları güncelleyelim UPDATE Musteri SET TelefonKod='(212)' OUTPUT INSERTED.MusteriId, DELETED.TelefonKod, INSERTED.TelefonKod INTO @Guncelle WHERE SehirId=2 --Güncellemiş kayıtları orijinal ve şu anki değerlerini listeleyelim SELECT * FROM @Guncelle
Aynı şekilde DELETE için de örnek verelim.
--Değişiklikleri aktacağımız tabloyu oluşturalım DECLARE @Silindi AS TABLE (MusteriId int, AdSoyad varchar(20)) --Tabloda MusteriId kolon 5'ten büyük olanları silelim DELETE Musteri OUTPUT DELETED.MusteriId, DELETED.AdSoyad INTO @Silindi WHERE MusteriId>5 --Güncellemiş kayıtları orijinal ve şu anki değerlerini listeleyelim SELECT * FROM @Silindi
PIVOT ve UNPIVOT Operatörleri
Excel kullanıcılarının vazgeçilmezi olan PIVOT uygulaması artık SQL Server 2005’te T-SQL aracılığıyla yapılabilimektedir. Ancak Excel’deki kadar yetenekli olduğunu söyleyemeyiz.
Aşağıdaki SIPARIS tablosunu düşünelim.

Bu tablodaki verileri aşağıdaki gibi gösterelim.
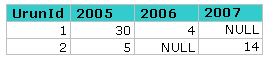
Önce bildiğimiz klasik CASE yöntemiyle gruplama fonksiyonlarını kullanarak bu işlemi gerçekleştirelim.
SELECT UrunId, SUM(case Donem when 2005 then Adet else null end) as [2005], SUM(case Donem when 2006 then Adet else null end) as [2006], --ISNULL(SUM(case Donem when 2006 then Adet else null end),0) as [2006], SUM(case Donem when 2007 then Adet else null end) as [2007] FROM SIPARIS GROUP BY UrunId
Aynı işlemi PIVOT ile gerçekleştirelim.
--Sadece ilgili kolonlar için bir tablo oluşturuyoruz. Temp table de olabilir. select UrunId , Donem , Adet into Siparis1 from SIPARIS SELECT UrunId, [2005], [2006], [2007] FROM Siparis1 PIVOT ( SUM(Adet) FOR Donem IN ([2005],[2006],[2007]) ) b
Veya geçici tablo oluşturmadan doğrudan kolonları Siparis tablosundan subquery mantığıyla okuyabiliriz.
SELECT UrunId, [2005], [2006], [2007] FROM ( SELECT UrunId, Donem, Adet FROM SIPARIS ) a PIVOT ( SUM(Adet) FOR Donem IN ([2005],[2006],[2007]) ) b
Aynı şekilde UNPIVOT operatörünü de kullanarak kolon ve satırların yerini değiştirebiliriz.
SELECT UrunId, [2005], [2006], [2007] INTO PivotTable FROM ( SELECT UrunId, Donem, Adet FROM SIPARIS ) a PIVOT ( SUM(Adet) FOR Donem IN ([2005],[2006],[2007]) ) b --SELECT * FROM PivotTable SELECT UrunId, Donem, Adet FROM PivotTable UNPIVOT (Adet FOR Donem IN ([2005],[2006],[2007]) ) as sonuc
CROSS APPLY ve OUTER APPLY Operatörleri
Sql 2005 ile birlikte gelmiş APPLY operatörü iki kaynak arasında dinamik join işlemi gerçekleştirir. Bu şu demektir, sol taraftaki tablodan satırları bir fonksiyonla join edip ve en önemlisi soldaki tabloya ait kolon değerini fonksiyona(fonksiyon içerisindeki tabloya) gönderebiliyor olmamızdır. Böylece gönderilen her değer için birer recordset oluşturulmuş olur. APPLY operatörü, CROSS ve OUTER işlemiyle birlikte kullanılır. APPLY operatörü, “ON” ifadesi olmayan JOIN yapısı gibi çalışır. OUTER APPLY seçeneği, joindeki sol tarafa ait tüm satırları getirir. Joinin diğer tarafındaki fonksiyonun döndürdüğü sonun içerisinde o satırların olup olmadığı önemsenmez. CROSS APPLY ise sadece fonksiyondaki satırlarla uyuşan sol tarafa ait satırlar döndürür.
Basit bir örnek ile başlayalım.
CREATE TABLE T1 ( ID int ) CREATE TABLE T2 ( ID int ) GO INSERT INTO T1 VALUES (1) INSERT INTO T1 VALUES (2) INSERT INTO T2 VALUES (3) INSERT INTO T2 VALUES (4) INSERT INTO T2 VALUES (5) GO SELECT COUNT(*) FROM T1 CROSS APPLY T2 -- 6 dönecektir. --Bu durumda SELECT COUNT(*) FROM T1,T2 cümlesinden bir fark olmamaktadır.
Daha gelişmiş bir örneğe bakalım. SqlTeam’de bulabileceğiniz bu örnek SQL Server 2005 ile default gelen AdventureWorks veri tabanı üzerinde çalışıyor.
Öncelikle dışarıdan müşteri Id’si alıp o müşterinin en yüksek satışlarını döndüren bir fonksiyon yazalım. Ayrıca en yüksek kaç satışının alınacağını parametre olarak alalım.
CREATE FUNCTION dbo.fn_GetTopOrders(@custid AS int, @n AS INT) RETURNS TABLE AS RETURN SELECT TOP(@n) * FROM Sales.SalesOrderHeader WHERE CustomerID = @custid ORDER BY TotalDue DESC GO
APPLY operatörünü kullanarak Customer tablosuyla bu fonksiyonu join edelim.
SELECT C.CustomerID, O.SalesOrderID, O.TotalDue FROM AdventureWorks.Sales.Customer AS C CROSS APPLY AdventureWorks.dbo.fn_GetTopOrders(C.CustomerID, 3) AS O ORDER BY CustomerID ASC, TotalDue DESC

EXCEPT ve INTERSECT operatörleri
EXISTS ve NOT EXISTS ifadeleri gibi çalışan EXCEPT(Farklı) ve INTERSECT(Kesişim) operatörleri iki tabloyu karşılaştırmak için kullanılır. EXCEPT operatörü, sol taraftaki kayıt setinde olup sağ taraftaki kayıt setinde olmayan kayıtları getirir. INTERSECT operatörü ise, her iki tarafta bulunan yani sol ve sağ tarafta bulunan kayıt setlerinin kesişimlerini getirir.
Musteri tablosunda her musterinin hangi tarihte nereye gittiği tutulmaktadır. Bu tabloya göre aşağıdaki query’leri yazabiliriz.
--İzmir'e gitmiş fakat İstanbul'a gitmemiş müşteriler SELECT AdSoyad FROM Personel WHERE Sehir='İzmir' EXCEPT SELECT AdSoyad FROM Personel WHERE Sehir='İstanbul' --Hem İzmir'e hem de İstanbul'a gitmiş müşterilerin SELECT AdSoyad FROM Personel WHERE Sehir='İzmir' INTERSECT SELECT AdSoyad FROM Personel WHERE Sehir='İstanbul'
Hata Yakalama(Exception Handling)
SQL Server 2005’ten önceki sürümlerde ne yazık ki T-SQL için güçlü bir hata yönetimi bulunmamaktaydı. SQL Server 2005’le birlikte Java’dan, C#’tan bildiğimiz try-catch bloğu eklendi. Hataya meyilli durumları TRY alanına, herhangi bir hata olduğu zaman nasıl davranılacağı da CATCH alanına yazılır.
BEGIN TRY
{ sql_statement | statement_block }
END TRY
BEGIN CATCH
{ sql_statement | statement_block }
END CATCH
[ ; ]
Ayrıca CATCH bloğunda yakaladığımız hatayla ilgili daha fazla bilgi almak için aşağıdaki fonksiyonlar kullanılır.
ERROR_NUMBER() : Hatanın kodunu döndürür,
ERROR_MESSAGE() : Hatayla ilgili detaylı açıklama verir.
ERROR_SEVERITY() : Hatanın önem derecesini döndürür.
ERROR_STATE() : Hatanın durum numarasını döndürür.
ERROR_LINE() : Hatanın oluştuğu satırı döndürür.
ERROR_PROCEDURE() : Hatanın oluştuğu stored procedure’un veya trigger’ın adını döndürür .
Aşağıdaki örnekte sıfıra bölünme gibi tipik bir hata yapılmış ve hatayla ilgili bilgiler okunmuştur.
BEGIN TRY
-- Sıfıra bölme işlemi
SELECT 1/0;
END TRY
BEGIN CATCH
-- İşlem hataya neden olacağı sistem, CATCH bloğuna düşecektir
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() AS ErrorState,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage;
END CATCH;
Aynı şekilde bir transaction çalıştırdığımızda olası bir hatada varsa yapılan işlemleri rollback etmeliyiz.
BEGIN TRANSACTION;
BEGIN TRY
-- Bir constraint hatası oluştuğunu düşünelim
DELETE FROM Musteri
WHERE MusteriID = 10;
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() as ErrorState,
ERROR_PROCEDURE() as ErrorProcedure,
ERROR_LINE() as ErrorLine,
ERROR_MESSAGE() as ErrorMessage;
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
END CATCH;
IF @@TRANCOUNT > 0
COMMIT TRANSACTION;
Büyük Veri Tipleri
Bilindiği SQL Server 2000’de VARCHAR ve VARBINARY tiplerinin maksimum büyüklüğü 8.000 ve NVARCHAR için de 4.000 karakter idi. Eğer sınırdan daha büyük bir veri(Large Object-LOB) kaydetmek istersek TEXT(2 GB), NTEXT(1 GB) veya IMAGE türlerinden birini tercih etmeliyiz. Fakat bu veri tipleriyle çalışmak çoğu zaman sıkıntılı olmaktaydı. Örneğin büyük veri tiplerinde karakter fonksiyonlarını sorunsuzca kullanamıyoruz.
SQL Server 2005 ile birlikte “MAX” belirteci geliştirildi ile tanımlanan büyük veri tipleri sunulmaktadır.
VARCHAR(MAX), NVARCHAR(MAX) ve VARBINARY(MAX) tipleri, 2Gb’a kadar veri alabilir. İlki 1.073.741.824 karakter ikicisi 536.870.912 karakter alabilir. Bu veri tipleri üzerinde LEN, SUBSTRING gibi string fonksiyonlarını kullanabiliyoruz.
SQL Server altında Assembly Kullanımı
SQL Server 2005 altında .NET kodlarını çalıştırabilmemiz T-SQL ile yapamadığımız işlemleri yapmamıza olanak tanımıştır. VB.NET veya C# ile yazdığımız bir metodu SQL Server rahatlıkla bir procedure, trigger içerisinde kullanabileceğiz. Bu işlem için yapılması gerekenler adımlar şöyledir:
.NET platformunda bir class library(.dll) oluşturulur. SQL Server 2005, doğrudan çalıştırılabilen dosyaları(.exe) kullanamaz. Class’taki üyelerin static modunda olması gerekir. Bu işlemden sonra “CREATE ASSEMBLY” ifadesiyle .NET Assembly, SQL Server 2005’e yüklenir, register edilir. Son olarak bu Assemby’e erişecek bir procedure, function veya trigger yazılım.
Öncelikle basit bir Toplama() metodu yazalım.
using System;
public class NetClassCs
{
public static int Toplama(int x, int y)
{
return x + y;
}
}
Bu kodlarımızı derleyip .dll olarak diske kayıt edip SQL Server’e register edelim.
CREATE ASSEMBLY NetAssembly FROM 'C:\NetClassCs.dll'
Son olarak bu Assembly’i kullanacak ve aynı parametreler sahip olması gereken bir procedure hazırlayalım.
CREATE PROCEDURE [dbo].[xp_CLRToplama] @Sayi1 [int], @Sayi2 [int] AS EXTERNAL NAME [NetAssembly].[NetClassCs].[Toplama]
Artık bu procedure’i çalıştırabiliriz.
DECLARE @Sonuc INT EXECUTE @Sonuc = xp_CLRToplama 3 , 5 SELECT @Sonuc AS CsharpToplama
SQL Server sunucusu üzerinde tanımlı CLR tabanlı Assembly’lerin bilgileri sys.assemblies tablosunda tutulur.
SQL Server 2005 ile birlikte T-SQL kapsamında sunulan yeni ifadeleri vermeye çalıştık. Tabi bunlar sadece birer özetti. Bu konulardan önemli olanları ileri dönemlerde detaylandıracağız.
Çok yararlandığım bir yazı Özellikle CLR Tabanlı Assembly’leri anlamamı sağladı. Teşekkürler.
ellerinize sağlık çok faydalı bir çalışma olmuş. örnekler çok iyi ve artık sitenizi takip edeceğim.saygılar
NTITLE()’ açıklamasında bir hata mı var.Anlayamadım.”Örneğimizde 8 kayıt var, bu kayıtlar arasında 5 grup oluşturalım. Sıralam yine Sehir kolonuna göre yapılacak.” ozaman 5 li grup 1 tane olup geriye 3 kayıt kalmaz mı ???
Merhaba,açıklama bir hata olduğunu sanmıyorum ayrıca doğru anlamışsınız. Evet önce 5’li grup 1’er tane dağıtalım. Ardından geri kalan 3’ü tekrar ilk gruptan itibaren 1’er tane dağıtalım. Bu durumda ilk 3 grupta 2’şer kayıt olmuş olur. Aynı şekilde eğer 3 grup yapmış olsaydık ilk 2 grup 3’er kayıt içerecek son grup 2 kayıt içermiş olacaktı. Bununla ilgili matematiksel bir formül vardı ama şu anda hatırlamıyorum.
teşekkürler şimdi anladım.
Guzel bir kaynak olmus.Tesekkuler.
teşekkürler ve ellerineze sağlık, çok faydalı bir paylaşım olmuş, konuların örnekleri ve sanlatım tarzı sade ama etkili.
EXCEPT konusunda, konu anlatılırken, ikinci EXCEPT yerine INTERSECT olacaktı değil mi? teşekkürler